


Алгоритм разделения реализации фразы на речь и паузы
Эталонная реализация фразы не содержит кадров с паузами и поделена на слова. Поэтому алгоритм применяется только к поступающей новой реализации фразы X(1),...,X(t),...,X(L), где L - длина новой реализации фразы. Требуется отделить кадры, содержащие речь, от кадров, содержащих паузу. Звонкие звуки речи, особенно гласные, имеют высокий уровень кратковременной энергии. По этому параметру они легко отделяются от пауз. Глухие звуки имеют низкий уровень кратковременной энергии. Однако большая часть их энергии лежит в области высоких частот, что приводит к большому числу переходов интенсивности сигнала через нуль. Это используется для отделения от пауз глухих звуков речи. Таким образом, совместное использование контуров кратковременной энергии Et и числа нулей интенсивности Zt позволяет точнее отделить речь от пауз. Под контуром параметра понимается последовательность значений параметра, вычисленных на каждом кадре X(t).
Предполагается, что первые 10 кадров не содержат речевого сигнала. По этому участку вычисляются среднее значение и дисперсия каждой из величин Et, Zt для определения статистических характеристик шума. Затем с учетом этих характеристик и максимальных на реализации фразы значений Et, Zt вычисляются пороги TE для кратковременной энергии сигнала и TZ для числа нулей интенсивности. Экспериментально были выбраны следующие формулы:
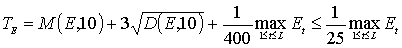 ,
,
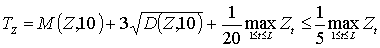 ,
,
где 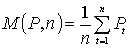 ,
,
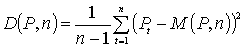 .
.
Каждому кадру X(t) мы должны поставить в соответствие двоичный признак bt, равный 1, если кадр содержит речь,и 0 - в противном случае. Сначала отмечают единицами кадры, на которых кратковременная энергия Et≥TE, и нулями - остальные кадры. Полученные отметки сглаживают медианной фильтрацией с окном шириной в 2h+1 кадров. (Например, h=3.) Признаки bt могут принимать всего два значения. Поэтому фильтрация сводится к тому, что последовательно для t=h+1,...,L-h значение bt заменяется на единицу, если 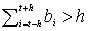 . В противном случае значение bt заменяется на ноль. В результате выделяются непрерывные участки, содержащие речь. Далее каждый такой участок пытаются расширить. Пусть, например, участок начинается с кадра X(N1) и заканчивается на кадре X(N2). Перемещаются влево от X(N1) (вправо от X(N2)) и сравнивают число нулей интенсивности Zt с порогом TZ. Это перемещение не должно превышать 20 кадров слева от X(N1) (справа от X(N2)). Если Zt превысило порог в три и более раз, то начало речевого участка переносится туда, где Zt впервые превышает порог. В противном случае началом участка считается кадр X(N1). Аналогично поступают и с X(N2). Если два участка перекрываются, то их объединяют в один. Таким образом, окончательно выделяются непрерывные участки, содержащие речь. Такие участки будем называть реализациями слов. Приведенный алгоритм позволяет перейти от сравнения реализаций фраз к сравнению реализаций слов.
. В противном случае значение bt заменяется на ноль. В результате выделяются непрерывные участки, содержащие речь. Далее каждый такой участок пытаются расширить. Пусть, например, участок начинается с кадра X(N1) и заканчивается на кадре X(N2). Перемещаются влево от X(N1) (вправо от X(N2)) и сравнивают число нулей интенсивности Zt с порогом TZ. Это перемещение не должно превышать 20 кадров слева от X(N1) (справа от X(N2)). Если Zt превысило порог в три и более раз, то начало речевого участка переносится туда, где Zt впервые превышает порог. В противном случае началом участка считается кадр X(N1). Аналогично поступают и с X(N2). Если два участка перекрываются, то их объединяют в один. Таким образом, окончательно выделяются непрерывные участки, содержащие речь. Такие участки будем называть реализациями слов. Приведенный алгоритм позволяет перейти от сравнения реализаций фраз к сравнению реализаций слов.