Факторный анализ. Главными целями факторного анализа являются: (1) сокращение числа переменных (редукция данных) и (2) определение структуры взаимосвязей между переменными, т.е. классификация переменных. Поэтому факторный анализ используется либо как метод сокращения данных, либо как метод классификации (термин факторный анализ впервые ввел Thurstone, 1931).
Предположим, вы хотите измерить удовлетворенность людей жизнью, для чего составляете вопросник с различными пунктами; среди других вопросов задаете следующие: удовлетворены ли люди своим хобби (пункт 1) и как интенсивно они им занимаются (пункт 2). Скорее всего, две переменные (ответы на два разных пункта) коррелированы между собой. Из высокой корреляции двух этих переменных можно сделать вывод об избыточности двух пунктов опросника.
Зависимость между переменными можно обнаружить с помощью диаграммы рассеяния. Полученная путем подгонки линия регрессии дает графическое представление зависимости. Если определить новую переменную на основе линии регрессии, изображенной на этой диаграмме, то такая переменная будет включать в себя наиболее существенные характеристики обеих переменных. Итак, фактически, вы сократили число переменных и заменили две одной.
Факторный анализ - это метод разведочного анализа; за информацией о подтверждающем факторном анализе обратитесь к разделу Моделирование структурными уравнениями
За дополнительной информацией о факторном
анализе обратитесь к разделу Факторный
анализ.
Фиксированные
эффекты (в дисперсионном анализе). Термин фиксированные
эффекты в контексте дисперсионного анализа
используется для обозначения факторов плана,
уровни которых заранее определяются
исследователем, а не случайно выбираются в ходе
эксперимента (факторы с неизвестными заранее
уровнями называются свободными эффектами).
Например, если мы хотим провести эксперимент по
проверке гипотезы, что повышение температуры
ведет увеличению агрессивности, мы, наверное,
провели бы наблюдение объектов в условиях
нормальной и повышенной температуры, и оценили
бы их агрессивность в этих условиях. Температура
в этом эксперименте будет фиксированным
эффектом, поскольку интересующие нас уровни
температуры преднамеренно фиксируются экспериментатором.
Для определения, является ли данный эффект в эксперименте случайным или фиксированным достаточно ответить на вопрос, каким образом выбираются (задаются) уровни соответствующего фактора в процессе повторения такого исследования. Например, если мы хотели бы повторить описанный пример, нам следовало бы выбрать те же самые уровни температуры из возможных уровней. Поэтому фактор "температура" в этом исследовании будет фиксированным фактором. Если же нас интересует зависимость агрессивности от температуры, нам следовало бы подвергнуть объекты воздействию набору случайно выбранных (из допустимого диапазона) температур. Уровни температуры в процессе повторения исследования, скорее всего, будут отличаться от уровней температуры, использованных первоначально, поэтому температуру можно рассматривать как случайный эффект.
Для получения дополнительной информации см.
разделы Дисперсионный анализ
и Компоненты дисперсии и
смешанная модель ANOVA/ANCOVA.
Фишера F-распределение.
F- распределение Фишера (для x > 0) имеет следующую функцию плотности (для| f(x) = { |
| x( |
0 ![]() x <
x < ![]()
![]() = 1, 2, ...,
= 1, 2, ..., ![]() = 1, 2, ...
= 1, 2, ...
где
![]() ,
, ![]() -
степени свободы
-
степени свободы
![]() - гамма
- функция.
- гамма
- функция.
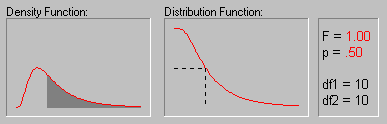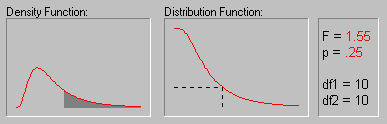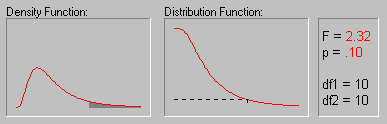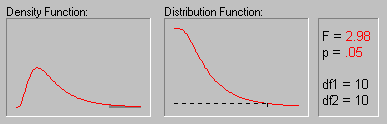
На приведенном выше рисунке показаны различные значения вероятностей (p-значения) для F-распределения с обеими степенями свободы равными 10.
Формат HTML. Это
сокращение (Hyper Text Markup Language) используется для
обозначения специального языка, разработанного
для создания документов в сети Интернет (World Wide
Web). HTML использует специальные метки (tags) для
идентификации текстовых или графических
элементов документа. Этот язык стал широко
использоваться во всемирной компьютерной сети с
1995 года, начиная с версии HTML 2.0, которая была
введена Internet Engineering Task Force (IETF) и могла работать со
всеми доступными в то время программами
просмотра Web-страниц. Дальнейшие разработки
этого языка осуществляются организацией World Wide Web
Consortium (W3C). Последняя версия HTML 3.2 включает все
инструменты, наиболее широко используемые с
начала 1996 года. Большинство программ, особенно
Netscape Navigator и Internet Explorer, распознают гораздо больше
HTML-меток (tags), чем включено в настоящий стандарт.
Формат JPEG. Это
сокращение используется для обозначения
графического формата записи Joint Photographic Experts Group.
Этот стандарт сжатой записи изображений ISO/ITU
использует дискретное косинус-преобразование.
Функция
активации нейронной сети. Функция, которая
используется для преобразования уровня
активации элемента (нейрона) в выходной сигнал.
Обычно функция активации имеет "сжимающее"
действие. Вместе с PSP-функцией
(которая применяется сначала) определяет тип
элемента сети.
Функция
выживания. Функция выживания (обычно
обозначаемая как R(t) ) является дополнительной к
функции распределения (т.е., R(t)=1-F(t) ). Функция
выживания иногда также называется функцией
надежности (поскольку она равна вероятности
выживания или невыхода из строя тестируемой
единицы до определенного момента времени t;
см., например, работу Lee, 1992).
Для получения дополнительной информации см.
описание модуля Анализ
выживаемости и раздел Распределение
Вейбулла и анализ надежности/времен отказов в
модуле Анализ процессов.
Функция ошибок
(для нейронных сетей). Служит для
определения качества работы нейронной сети во время
итерационного обучения и последующих рабочих
запусков. Градиент функции ошибок используется в
формулах алгоритмов итерационного обучения (Bishop,
1995).
См. также разделы о нейронных
сетях и о функции потерь.
Функция ошибок городских кварталов (для нейронных сетей). Вычисляет расстояние между двумя векторами как сумму модулей разностей их компонент. Менее чувствительна к выбросам, чем квадратичная функция ошибок, но при этом обычно дает худшие результаты обучения (Bishop, 1995).
См. также раздел о нейронных
сетях.
Функция потерь. Функция потерь (этот термин был впервые использован в работе Wald, 1939) - это функция, которая минимизируется в процессе подгонке модели. Она представляет выбранную меру несогласия наблюдаемых данных и данных, "предсказываемых" подогнанной функцией. Например, в большинстве традиционных методов построения общих линейных моделей, функция потерь (часто называемая наименьшими квадратами) вычисляется как сумма квадратов отклонений от подогнанной линии или плоскости. Одним из свойств (которое обычно рассматривается как недостаток) этой распространенной функции потерь является высокая чувствительность к наличию выбросов.
Распространенной альтернативой минимизации
функции потерь наименьших квадратов (см. выше)
является максимизация функции правдоподобия или
логарифма функции правдоподобия (или
минимизация функции правдоподобия со знаком
минус; термин максимум правдоподобия был впервые
использован в работе Fisher, 1922a). Эти функции обычно
используются для подгонки нелинейных моделей. В
общих словах функция правдоподобия определяется
как:
L=F(Y,Модель)=![]() ni=1 { p[yi , Параметры
модели(xi)]}
ni=1 { p[yi , Параметры
модели(xi)]}
Таким образом, можем вычислить вероятность
(обозначенную как L, от слова likelihood -
правдоподобие) появления конкретных значений
зависимой переменной в выборке при заданной
регрессионной модели.